
Enter Apache Spark and Hadoop, two heavyweights meticulously crafted to conquer the challenges of processing, storing, and dissecting colossal data troves. Apache Hadoop stands tall as an open-source powerhouse, flaunting its prowess in orchestrating reliable, scalable, and distributed computing landscapes. Meanwhile, Apache Spark emerges as the dynamic hero, wielding its arsenal of big data processing capabilities.
Nestled snugly within the vibrant Hadoop ecosystem, Spark reigns as a crown jewel, a go-to cluster computing framework crafted to revolutionize how we handle data. Together, they traverse the distributed realm, orchestrating intricate operations seamlessly across clusters with finesse and efficiency.
These two open-source technologies, Hadoop and Spark, simplify our lives significantly, standing as close competitors in the realm of data analytics. While they belong to the Apache projects umbrella, each possesses distinct use cases. Despite their varied advantages and disadvantages, a comparison easily determines the more suitable choice for business needs.
Let’s delve deeper into understanding these technologies by thoroughly analyzing their benefits and use cases.
Understanding Hadoop

The origins of the Apache Hadoop project trace back to the late 1990s when Doug Cutting and Mike Cafarella conceived it at Yahoo. Since then, it has evolved into one of the most widely utilized distributed file systems globally.
Built in Java, the Hadoop framework facilitates scalable processing of extensive datasets across clusters of commodity hardware, thereby enabling high-performance computing. Essentially, Hadoop offers a cost-effective means of storing and processing data, employing a distributed processing model that grants users access to information without storing it on a single machine.
Businesses, governments, and individuals utilize Hadoop for distributed storage, database management, and cluster computing, employing the MapReduce programming model to process vast data sets. It was primarily crafted to address the limitations of traditional relational databases, aiming for faster processing of large data sets, especially in the realm of web services and internet-scale applications.
Hadoop encompasses four major modules:
- Hadoop Distributed File System (HDFS): Manages and stores large data sets across clusters, handling both unstructured and structured data, accommodating various storage hardware from consumer-grade HDDs to enterprise drives;
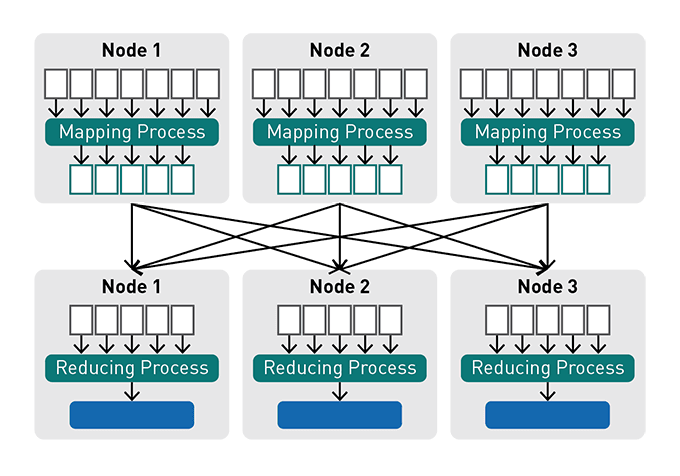
- MapReduce: Processes data fragments in HDFS by assigning separate map tasks in the cluster, consolidating chunks into the desired result;
- Yet Another Resource Negotiator (YARN): Manages job scheduling and computing resources.
Also known as Hadoop Core, houses common utilities and libraries, acting as a support system for other modules.
Understanding Spark
Apache Spark, an open-source project by Databricks, supports processing fast data sets in real-time. It is provided as a service by Databricks, offering over 100 pre-built applications across diverse domains. Spark caters to interactive queries, machine learning, big data analytics, and streaming analytics.
As an in-memory data processing framework, Spark was conceived at UC Berkeley as an extension of the big data ecosystem supported by Hadoop, Apache HBase, Hive, Pig, Presto, Tez, and other components. It was developed to enhance MapReduce efficiency without compromising its advantages. Spark’s primary user-facing API is the Resilient Distributed Dataset (RDD).
Utilizing Scala and Python programming languages, Spark offers a distributed computing framework for significant big data processing. Its key components include:
- Apache Spark Core: Responsible for essential functions like task dispatching, scheduling, fault recovery, and I/O operations, serving as the foundation for the entire project;
- Spark Streaming: Enables the processing of live data streams from various sources like Kinesis, Kafka, Flume;
- Spark SQL: Gathers structured data and processes information regarding data structures;
- Machine Learning Library (MLLib): Houses a diverse library of machine learning algorithms, aiming to enhance scalability and accessibility in machine learning;
- GraphX: Features APIs facilitating graph analytics tasks.
The framework employs an optimized distributed programming model, executing computations across clusters of machines connected via high-speed networks. Specifically designed for large-scale data processing, Spark breaks down massive data sets into smaller, independently processable tasks, reducing the burden of handling extensive data.
Hadoop vs. Spark: Key Differences
Hadoop, an established enterprise-grade platform, offers a complete distributed file system for data storage and management across clusters. In contrast, Spark, a comparatively newer technology, primarily aims to simplify working with machine learning models.
Both Apache Hadoop and Apache Spark reign as titans in the big data realm, with distinct advantages and disadvantages. Choosing between them proves challenging, lacking a clear “winner” or definitive answer. Opting for the most suitable framework for a business often hinges on existing infrastructure, team expertise, and long-term strategy.
Here’s a concise comparison between Hadoop and Spark in a tabular format:
| Aspect | Hadoop | Spark |
|---|---|---|
| Processing Paradigm | Primarily MapReduce paradigm | Offers a wider range of processing paradigms, including batch, real-time, streaming, graph processing, and more |
| Speed | Slower due to disk-based processing | Much faster due to in-memory processing and optimized DAG execution engine |
| Processing Model | Batch-oriented | Supports both batch and real-time/stream processing |
| Data Processing | Disk-based processing | In-memory processing for iterative and interactive jobs |
| Fault Tolerance | Relies on replication for fault tolerance | Uses lineage information and resilient distributed datasets (RDDs) for fault tolerance, reducing disk I/O |
| Ease of Use | More complex due to MapReduce programming model and configurations | Easier to use due to high-level APIs (like DataFrame, Dataset) and more concise programming models |
| Libraries and APIs | Hadoop ecosystem has various tools and libraries (e.g., Hive, Pig, HBase) | Spark provides built-in libraries for machine learning (MLlib), graph processing (GraphX), SQL (Spark SQL), and streaming (Spark Streaming) |
| Real-time Processing | Limited capabilities for real-time processing | Designed for real-time processing with features like Spark Streaming and Structured Streaming |
This table highlights key differences between Hadoop and Spark, showcasing their distinct characteristics, strengths, and limitations in various aspects of big data processing.
Let’s dissect the differences between Hadoop and Spark across various parameters:
Performance
Performance stands as the paramount metric driving the success of any data analytics software or platform. Comparing the performance of Hadoop and Spark presents challenges due to numerous factors influencing big data environment performance, including software choice, hardware capabilities, number of nodes, and storage availability.
Hadoop excels in overall performance when accessing locally stored data on HDFS. However, Spark outshines Hadoop in in-memory processing capabilities, claiming to be 100 times faster through MapReduce with sufficient RAM for computing. Spark set a world record in 2014 for sorting data on disk, proving three times faster than Hadoop, utilizing ten times fewer nodes to process 100TB data on HDFS.
Spark’s superior performance stems from its reliance on RAM for data storage and processing, avoiding intermediate data write/read to storage disks. Conversely, Hadoop employs diverse data storage levels and processes data in batches using MapReduce.
Despite Spark’s apparent advantage, when data surpasses available RAM capacity, Hadoop becomes the logical choice.
Cost
Comparing the pricing of these two big data processing frameworks directly is relatively simple as both platforms are open-source and free. However, determining Total Cost of Ownership (TCO) requires considering infrastructure, development, and maintenance expenses.
Hadoop operates on various data storage devices, keeping hardware costs relatively low. Conversely, Spark relies on in-memory computation, demanding substantial RAM, elevating hardware expenses.
Availability of resources for application development influences costs. Hadoop’s extended presence facilitates the availability of experienced developers, reducing remuneration requirements. In contrast, finding resources for Spark proves relatively challenging, affecting costs.
Notably, although Hadoop appears more cost-effective, Spark’s accelerated data processing almost equals the Return on Investment (ROI).
Data Processing
Both frameworks process data in distributed environments, employing different methods. Spark excels in real-time processing, while Hadoop dominates in batch processing scenarios.
Hadoop stores data on disk and conducts parallel analysis over distributed systems. MapReduce handles vast data volumes with minimal RAM dependency, ideal for linear data processing.
Spark operates with RDDs, storing elements across clusters in node partitions. Partitioning RDDs allows Spark to perform operations in parallel on the closest nodes, utilizing Directed Acyclic Graphs (DAG) to track RDD performances.
Spark efficiently handles live streams of unstructured data via high-level APIs and in-memory computation, storing data across partitions. However, a single partition can’t expand to other nodes, imposing limitations.
Fault Tolerance
Both frameworks ensure reliability in handling failures, employing differing fault-tolerance approaches.
Hadoop’s fault tolerance relies on data replication across nodes, rectifying issues by reconstructing missing blocks from alternate locations. A master node oversees slave nodes, reassigning tasks if any nodes become unresponsive.
Spark utilizes RDD blocks for tolerance. It tracks unchangeable dataset creation, restarting processes upon system errors. Employing DAG workflow tracking, Spark rebuilds data across clusters, managing issues in distributed data processing.
Scalability
Hadoop boasts superior scalability due to its utilization of HDFS for big data management. As data volumes increase, Hadoop easily accommodates rising demands. Conversely, Spark, lacking a file system, relies on HDFS for large data handling, limiting scalability.
Both frameworks accommodate thousands of nodes, with no theoretical ceiling on server additions or data processing capacities. In the Spark environment, studies have demonstrated the effectiveness of 8000 machines collaborating on petabyte-scale data. Hadoop clusters can extend to tens of thousands of machines handling close to exabyte-scale data.
Ease of Use and Programming Language Support
Spark supports multiple programming languages—Java, Python, R, and Spark SQL—enhancing user-friendliness and enabling developers to opt for preferred languages.
Hadoop, Java-based, supports Java and Python for MapReduce code writing. Its user interface lacks interactivity but integrates with tools like Hive and Pig for complex MapReduce programming.
Spark’s interactivity is evident via Spark-shell, offering Python or Scala-based interactive data analysis and prompt query feedback. Code reusability in Spark streamlines application development, combining historic and stream data for efficiency.
Security
Hadoop holds an advantage in security features compared to Spark. Spark’s default security settings are relatively less secure, necessitating additional authentication measures such as event logging or shared costs. However, these might prove insufficient for production workloads.
Hadoop boasts multiple authentication features like Kerberos, Ranger, ACLs, and encryption, augmenting security significantly. Spark necessitates integration with Hadoop to attain comparable security levels.
Machine Learning
Spark exhibits promise in machine learning due to its iterative in-memory computation, overcoming performance issues encountered by Hadoop’s MapReduce in handling machine learning algorithms. Spark’s default machine learning library and data science tools bolster classification, pipeline construction, regression, and more.
Hadoop’s MapReduce, dividing jobs into parallel tasks, struggles with data science machine learning algorithms due to I/O performance issues. Mahout, Hadoop’s primary machine learning library, relies on MapReduce for various tasks, presenting limitations.
Resource Management and Scheduling
Hadoop relies on external solutions for scheduling and resource management, utilizing YARN for resource management and tools like Oozie for workflow scheduling.
Spark integrates resource management and scheduling within its framework, employing DAG Scheduler for dividing operations into stages, handling tasks efficiently.
Using Hadoop and Spark Together
Combining Hadoop and Spark offers immense benefits, as Hadoop excels in data storage, while Spark shines in data processing. Leveraging Hadoop’s data storage capabilities in conjunction with Spark’s analytical functions and DataFrames allows real-time big data analysis.
Spark was developed to complement rather than replace Hadoop. Integrating Spark with HBase, Hadoop MapReduce, and other frameworks empowers Hadoop developers to enhance processing capabilities.
Spark seamlessly integrates into various Hadoop frameworks like Hadoop 1.x or Hadoop 2.0 (YARN), regardless of administrative privileges, facilitating deployment via YARN, SIMR, or standalone methods.
Hadoop Use Cases
Hadoop finds applications in market analysis, scientific research, financial services, web search, and e-commerce, especially suited for scenarios requiring processing large data sets surpassing available memory capacity. Its cost-effectiveness makes it ideal for low-budget data analysis infrastructure and empowers retailers to understand and serve their audiences better. In industries where time is not a constraint, like preventive maintenance in machinery-intensive sectors or IoT devices data analysis, Hadoop proves beneficial.
Spark Use Cases
Spark excels in real-time stream data processing, crucial for industries requiring immediate insights. Its in-memory computation, iterative algorithm support, machine learning library, and real-time analytics capabilities benefit healthcare services, gaming industry for targeted advertising, and industries necessitating multiple parallel operations.
Spark, an open-source distributed computing system, finds application in various domains due to its speed, ease of use, and versatility. Some prominent Spark use cases include:
- Big Data Processing: Spark is excellent for processing large volumes of data in diverse formats. It’s commonly used for batch processing, real-time stream processing, and interactive querying;
- Machine Learning: Spark’s MLlib library offers scalable machine learning algorithms. It enables the training and deployment of machine learning models on big data sets efficiently;
- Streaming Data Analysis: Spark Streaming enables real-time processing of streaming data, making it suitable for applications like monitoring social media feeds, IoT devices, and financial market analysis;
- Graph Processing: With GraphX, Spark allows processing and analyzing graph data structures, making it beneficial for social network analysis, fraud detection, and recommendation systems;
- Data Warehousing: Spark SQL facilitates querying structured data using SQL, making it useful for data warehousing tasks and interactive analytics;
- Log Processing: Analyzing logs from various sources like web servers or applications for monitoring, troubleshooting, and security analysis is simplified using Spark’s capabilities;
- Bioinformatics: Spark has applications in genomics and bioinformatics for analyzing vast amounts of biological data efficiently;
- Financial Analysis: In finance, Spark can be used for risk analysis, fraud detection, algorithmic trading, and real-time monitoring of market data;
- Healthcare Analytics: Spark can process and analyze large healthcare datasets for tasks like patient record analysis, predictive analytics, and personalized medicine.
- Recommendation Systems: Collaborative filtering techniques in Spark are suitable for building recommendation systems used in e-commerce or content platforms;
- Image and Video Processing: Spark can handle large-scale image and video processing tasks, such as object detection, image recognition, and video analysis;
- Natural Language Processing (NLP): Spark’s ability to handle large text data makes it suitable for sentiment analysis, text classification, language translation, and information retrieval.
These applications showcase the versatility of Apache Spark across different industries, demonstrating its effectiveness in handling and processing large volumes of data for various purposes.
In finale
Hadoop specializes in processing and analyzing extensive data sets that exceed drive capacities, primarily serving big data analysis needs. Spark, as a general-purpose cluster computing framework, fast-tracks large dataset processing, rendering it ideal for real-time analytics.
This comparison unveils the key disparities between Hadoop and Spark, the leading choices in the big data arena. It offers insights into selecting one over the other based on specific requirements and scenarios. To conclude, Spark was developed to enhance Hadoop’s capabilities. Leveraging both frameworks simultaneously enables businesses to enjoy the combined benefits of Hadoop’s storage prowess and Spark’s analytical efficiency.